The UK government is consulting on proposals to overhaul long-standing copyright laws in a bid to give AI developers easier access to material on which to train their systems, but the nation’s creative industries are up in arms. C21 investigates how the situation might pan out.
On February 25 this year, the UK government closed a consultation on updating existing copyright laws to ensure the nation’s creative industries continue to thrive while at the same time allowing nascent artificial intelligence (AI) innovation to flourish.
Three days later, OpenAI – maker of groundbreaking AI chatbot ChatGPT – released text-to-video sibling Sora to the Great British public, an early test version of which prompted US actor and filmmaker Tyler Perry to put the US$800m expansion of his Atlanta studio on hold last year.

Chris Bryant
House of Commons
Ask ChatGPT what Sora is trained on and it will offer you a variety of ‘likely’ sources: “While OpenAI hasn’t disclosed the exact details of Sora’s training data, here’s what we know (based on public info and typical practices in training generative models like this),” says the bot.
“Likely training sources: publicly available videos and images (e.g., from open datasets, video-sharing sites with permissive licenses); licensed data – OpenAI may have used video or image datasets obtained through legal agreements with content providers; text data – since Sora generates video from text prompts, it likely also uses large corpora of text (similar to GPT models) to understand language, context, and storytelling.”
ChatGPT adds that, according to OpenAI: “It’s not explicitly trained on private user data from OpenAI products (like ChatGPT conversations), unless users have opted in; it’s not trained on copyrighted content without permission (e.g., copyrighted TV shows, movies, or proprietary video datasets).”
This last bit is obviously critical to the creative industries – not only those of the UK but all around the world. And Sora, released in the US on December 9, is just one among myriad AI tools that could not exist if it weren’t for the reams of content they feed off – some of it publicly available and copyright-free but much (we are left to assume or prove) unlicensed and potentially infringing on the owner’s right to royalties.
While moves are underway in many countries to bring legislation in line with these challenges, advances in AI are moving so fast it’s almost impossible to keep pace. At the same time, nation states do not wish to stifle innovation and are locked in a global arms race to ensure they secure a competitive edge in this space. Hence, the UK’s Copyright & Artificial Intelligence consultation, which kicked off on December 17 last year, soon after OpenAI released Sora in the US.
Conflicts of interest
Chris Bryant, UK minister for the creative industries, arts and tourism, spelled out these apparently conflicting interests in presenting the consultation (a joint initiative from the nation’s intellectual property office, department for science, innovation and technology, and department for culture, media and sport) to parliament.
“The creative industries are central to our economic future, and we are determined to help them flourish. The same is true of artificial intelligence – both as an enabler of other industries, including the creative industries, and as a sector in its own right,” he said.
“Strong copyright laws have been the bedrock of the creative industries, but as things stand, the application of UK copyright law to the training of AI models is fiercely disputed. Rights holders are finding it difficult to control the use of their works to train AI models, and they want and need a greater ability to manage such activity and to be paid for it. Likewise, AI developers, including UK-based start-ups, are finding it difficult to navigate copyright law and complain that the legal uncertainty means that they are unable to train leading models in the UK.”
“The status quo cannot continue,” Bryant went on. “It risks limiting investment, innovation and growth in the creative industries, the AI sector and the wider economy. Neither side can afford to wait for expensive litigation – either here or in the US – to clarify the law, not least because courts in different jurisdictions may come to different conclusions and individual cases may not provide clarity across the sector. Nor can we simply rely on voluntary co-operation. That is why we think the government must take proactive and thoughtful action that works for all parties.”
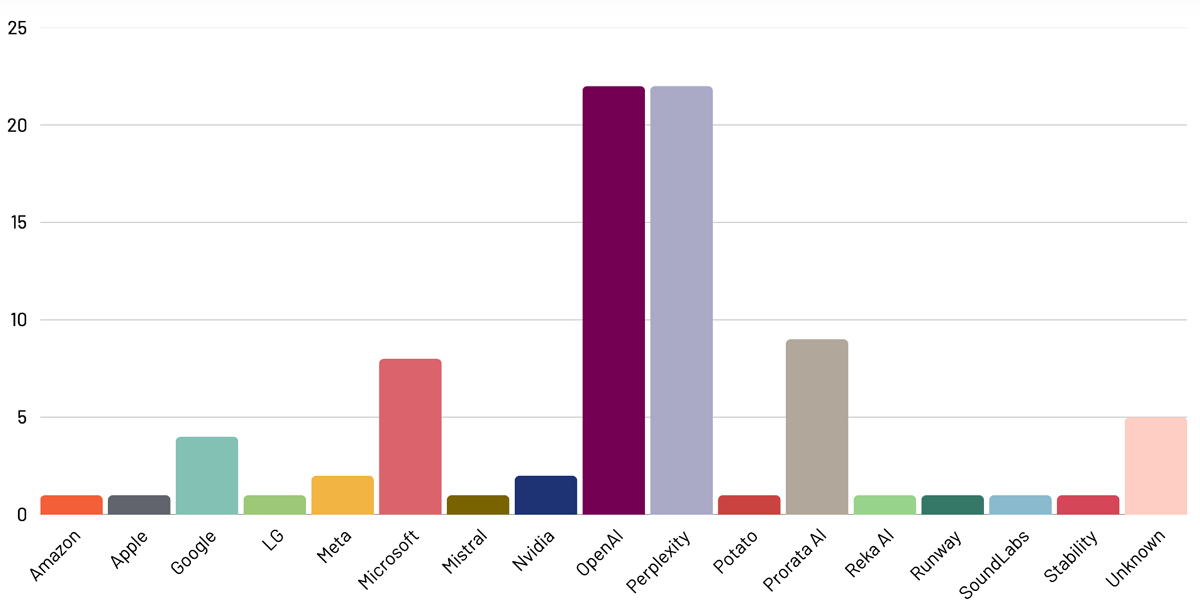
Number of known commercial agreements, by licensee/AI developer (n=83)
(click to enlarge)
The minister maintained that the government’s objectives on the issue are to give IP owners greater control and improve their ability to get paid, while at the same time granting AI developers greater access to high-quality content to train their systems. He stressed too, that part of this process means also leaning on such companies to be more transparent about their use of it.
The endeavour is complex and these extracts from Bryant’s speech highlight the central paradoxical problem: how on the one hand to ensure creatives are rewarded for their labours while on the other allowing AI sufficient free rein to achieve its potential. Some might argue these dual ambitions are incompatible and, as Bryant also pointed out, differing laws are already being applied in different countries, with litigation the favoured route of some.
Jurisdiction is an added complication, especially given that certain territories – notably China (home to the ChatGPT challenger DeepSeek which nearly crashed the US stock market with its release this January) – have historically had a more relaxed attitude to rights protection than others.
In the US, Game of Thrones writer George R R Martin, Bosch creator Michael Connelly, The Firm’s John Grisham and other scribes joined an Authors Guild class-action lawsuit against OpenAI and investor Microsoft in September 2023 alleging “blatantly unfair conduct in stealing copyright protected books.”
“The efforts by AI companies to license books for training is important but in no way addresses – and in fact confirms – past and ongoing violations, and the growing licensing market for material for AI training,” said the Guild in its latest update on the ongoing case.
Elsewhere in the world of publishing, the New York Times has also taken legal action against OpenAI, while ABC in Australia, CNN and The Guardian have blocked the firm’s bots from trawling their sites. Fellow AI purveyors Stability AI, Midjourney and Runway are all up against similar litigation.

Number of known commercial agreements, by licensor/content provider (n=83)
(click to enlarge)
Other parties, however, such as Associated Press, Axel Springer, the Financial Times and News Corp, have struck lucrative licensing deals with OpenAI – the latter arrangement worth a reported US$250m over five years – while a pact between Google and Reddit is said to be valued at US$60m a year, and Shutterstock (in the midst of a US$3.7bn acquisition by Getty Images) made over US$100m from AI licensing partnerships with OpenAI, Meta, Google, Amazon and others.
As far as TV is concerned, Bloomberg reported last year that Meta, Google, Microsoft and the like are willing to pay “tens of millions of dollars” to Hollywood studios for the right to ingest their content. No such pacts have yet been made public, except for one between Lionsgate and Runway, though the somewhat opaque arrangement is not one that’s described as being based on licensing.
Bridging the gap
Last year, C21 wrote extensively about the emergence of a string of US start-ups aiming to bridge the gap between TV catalogue owners and AI companies willing to pay substantial sums for their product. Dave Davis, co-founder of one such venture, Calliope Networks – snapped up by New York-headquartered Protege in December – told us: “AI is going to disrupt lives, but it’s inevitable that it’s coming and whether Calliope exists, then licenses titles to these companies, or not, they are scraping a lot of great high-quality material. Moreover, if content owners don’t engage with AI companies, I believe judges and policymakers will essentially force their hand. Mandatory licensing is historically a terrible thing for content owners.”
This argument brings us full circle to the UK government’s Copyright & Artificial Intelligence consultation and some controversial proposals at the heart of it. Bryant put forward ideas for “a new system of rights reservation, whereby rights holders can withhold their content from being used unless and until it has been licensed” and “an exception to copyright law for text and data mining where rights holders have licensed their content or otherwise chosen not to reserve their rights.” These suggestions caused uproar.

ChatGPT’s text-to-video offshoot Sora
Sora
In January, Paul McCartney told the BBC such changes would allow AI companies to “rip off” artists. Shortly after, the former Beatle added his name to an open letter published in The Times newspaper – also signed by the likes of Stephen Fry, James Bond producer Barbara Broccoli, Elton John, Dua Lipa and Kate Bush – warning that the proposals represent “a wholesale giveaway of rights and income from the UK creative sectors to big tech.”
Bush was also among a group of 1,000 musicians who released a silent album in February, on the same day the consultation closed, titled Is This What We Want? while a cohort of national, regional and local news organisations launched a campaign called Make It Fair, accusing the government of planning to “weaken the law and essentially make it legal to steal content.”
These voices joined those of other industry collectives, notably the Creative Rights In AI Coalition – a group of publishers, authors, artists, photographers, and more – which debuted on the eve of the consultation and include among its ranks UK independent TV producers’ trade association Pact, broadcasters’ union Bectu, the Motion Picture Association, actors’ rep Equity and Directors UK.
Pact also joined forces with another alliance comprising All3Media, Banijay, BBC, Channel 4, Fremantle, ITN, ITV and more also seeking guarantees that the government won’t ride roughshod over 300-year-old copyright legislation, which they maintain has worked well to date, in the rush to put AI innovation at the centre of its broader industrial strategy.

John McVay
“It’s vitally important that the government listens to the concerns of UK rights owners who have generated billions for the UK economy and whose creativity enriches the lives of UK citizens and others around the world. The UK’s position as a global leader in the creative industries has been hard fought for and must not be squandered lightly on the altar of technological progress that has yet to prove its economic value for the country and its citizens,” said Pact CEO John McVay. “AI helping to improve medical research and treatments is one thing, AI plundering the collective works of creatives to enrich companies in other countries is entirely another.”
It’s the government’s suggestions of a “new system of rights reservation” and an “exception to copyright law” which are among these constituents’ greatest concerns – an approach, they maintain, that would permit technology companies to train their AI models on creative works including films, TV shows and audio recordings without permission, unless creators actively opt-out.
The film and TV coalition’s consultation response warns that this kind of change is “currently not workable, would not achieve the government’s aims, and would undermine the success of the creative sector.”
Others have raised the same objection. The International Confederation of Societies of Authors and Composers, which describes itself as the world’s leading network of authors societies and is presided over by ABBA co-founder Björn Ulvaeus, has urged the UK government to reconsider its ideas, which it too argues “place the burden on creators to ensure that their works are protected.”
CREATe, the Centre for Regulation of the Creative Economy, is a Glasgow University-based research centre established more than a decade ago to explore the intersection of copyright and new business models within the creative industries and so is exceptionally placed to contribute to the present debate.
Opting in or opting out?
To coincide with its submission to the Copyright and AI consultation, the organisation published its own findings on the extent of existing AI licensing activities in the UK in which it identified more than 80 commercial agreements between content owners and AI developers. News and media outfits are by far the most actively engaged in such arrangements, according to CREATe, while OpenAI and Perplexity lead the established tech giants Amazon, Apple, Google, Meta and Microsoft in reaching these deals.
“The UK government’s favoured option for reform is an ‘opt-out’ model; essentially, that AI training based on copyrighted works should only be permitted so long as the rightsholder has not reserved their rights (i.e., opted-out),” says CREATe, steered by Glasgow University professor of intellectual property law Martin Kretschmer. “However – this data indicates – that the AI licensing economy is already happening, and at scale. Opting-out may offer an illusion of control, while the rewards flow in predictable ways.
“In our view, the reservation of rights (opt-out) is difficult to implement technically, will increase costs and create hurdles to market entry. The default should remain an opt-in framework.”
UK shadow minister for science, innovation and technology Dr Ben Spencer also accused the government of having already “picked one side” in the debate with its “preference for a data mining opt-out for the creative industries” that will “place extra burdens on creators to protect their intellectual property.”

Ben Spencer
House of Commons: Laurie Noble
But creative industries minister Bryant pushed back on the claim in parliament in December.
“I want to contest the idea that we have sided with one or the other,” he said. “There is a legitimate problem, which is that AI companies and the creative industries are at loggerheads in the courts in several different jurisdictions on several different points which are moot at the moment. We do not think that simply standing by the present situation will suffice because the danger is that in two or three years’ time all UK content will have been scraped by one or other AI developing company somewhere else in the world if there is no legal clarity in the UK. I would like to be able to bring all that home so that AI operators can work in this country with security under the law, using UK copyright that has been licensed and paid for, because that is another potential revenue stream for creators in this country.”
Bryant described the ‘opt-in/opt-out’ debate as a “false dichotomy.”
“That is why we have landed on the term ‘rights reservation’,” he said. “A lot of the material out there is not copyright. That is either because it is long out of copyright – the law for most works lasts for 70 years after the death of the author or the first publication of the work – or because some artists have categorically decided not to retain their copyright.
“I fully understand that there will be people in the creative industries who will be worried about what we are saying, but I want them to understand that this package comes as a whole. We will proceed only if there is a proper system of rights reservation. Then, I think, everybody has a chance of prospering in the UK.”
C21 understands the Copyright & AI consultation received more than 11,000 submissions from interested parties so there is much to sift through if all are to be considered. There have been hints in some quarters that the government may already be rethinking its “rights reservation” proposal but no word yet on when it will publish its conclusions.
A spokesman says “in due course,” while ChatGPT says it can keep you informed of any updates.